Open Source Data and Analytics Architecture
Introduction
I will update this when I begin the project. The goal here is to explore and create a tech stack to support modern data and analytical workloads, using entirely open source software. Ideally, I’ll be able to scale it to terabytes and then share that template and the guide as a public resource.
Currently, I’m thinking of the following tools, as part of a non-exhaustive list of the stack:
OS/Environment:
zsh/bash
Project and Package Management:uv
Collaboration and Source Control:Github
Documentation:Quarto
Data Modeling:dbt
Containerization:Docker
Container Orchestration:Kubernetes
OLTP Database:PostgreSQL
OLAP Database:DuckDB
Batch Ingestion:Python
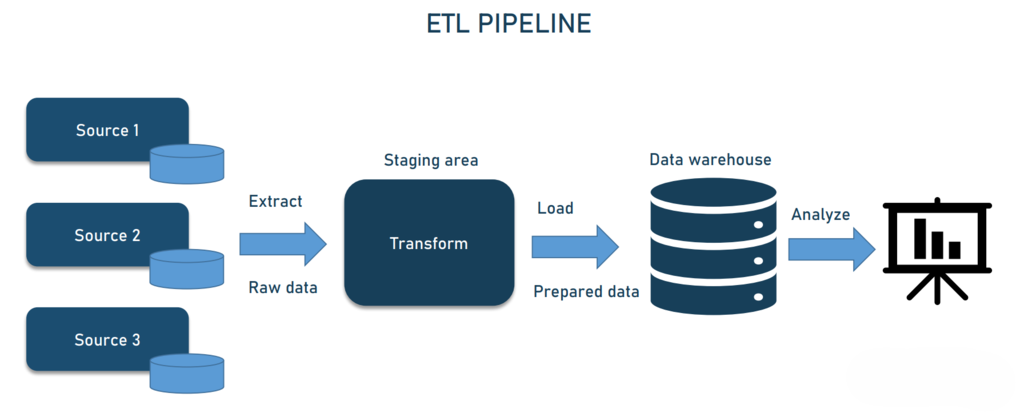
ETL:dbt
Testing:pytest
Data Quality:Great Expectations
Metadata:Unity Catalog
ETL Orchestration:Airflowand/orDagster
Streaming Ingestion:Kafka
General workflow I’m envisioning:
- Initialize project with
uv, add basic dependencies for the environment - Create the repo with the GitHub CLI
- Set the remote as the upstream and do the initial commit
- Initialize the
quartoanddbtprojects as subdirectories of the main,uvproject directory - Create the
postgrescontainer withdocker, use this to initialize thepostgresdatabase (Prod) - In your
uvenvionrment, initialize theduckdb(Dev/Test) persistent database- Simpler to work quickly with
duckdb,postgreshas more configurations/overhead, but is better for long term persistent
- Simpler to work quickly with
- Use
python and duckdbto ingest the initial batch of raw data - Use
dbtto define the data model,pytestto define the basic tests, andgreat expectationsto define data quality - Initialize the
unity cataloginstance, add the connection information (Dev/Test/Prod) - Generate metadata and lineage
- Start scheduling and orchestrating jobs
- Potentially scale system up to handle stremaing data